
Originally Posted by
Corky34

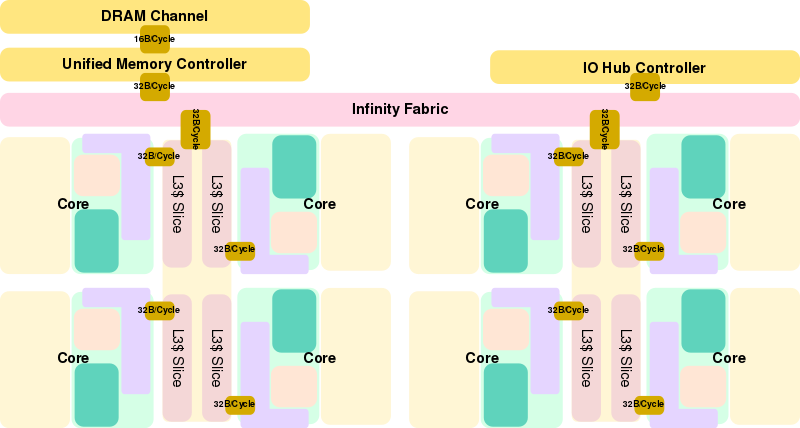
True but I'm unsure how much more they could get out of memory latency, with Zen the cores in each CCX don't have direct access to RAM, the memory controllers are not integrated into the cores themselves like they are with Intel, they're attached to the infinity fabric's (IF) scalable data fabric (SDF), it adds an extra step compared to Intel.
That's not to say one is better or worse than the other as it's horses for course but it seems AMD have picked most of the low hanging fruit in terms of RAM latency already.





 LinkBack URL
LinkBack URL About LinkBacks
About LinkBacks


 Reply With Quote
Reply With Quote



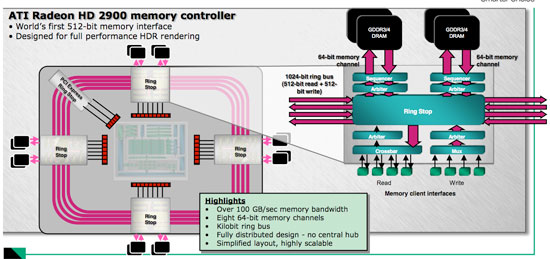
 ), that means charging up a long wire which takes time so limits clock speed.
), that means charging up a long wire which takes time so limits clock speed. And they had the cheek to poke holes in AMD's implementation, the networking world mostly moved away from the ring bus topology for a reason, Intel.
And they had the cheek to poke holes in AMD's implementation, the networking world mostly moved away from the ring bus topology for a reason, Intel.


