




 LinkBack URL
LinkBack URL About LinkBacks
About LinkBacks

Hi,
So that the details of what I've done don't get buried deep in a chatty thread, here's my problem.
When running the F@H smp client with the BIGADV flag set, this utilises all 12 threads (6 real, 6 hyperthreaded)
The NVidia GTX 480 uses CPU cycles to operate (so much for running the GPGPU without a CPU eh NVidia? Wonder if that's a Windows or CUDA requirement? Wonder what the hell the Chinese are running their Tesla supercomputer on....)
My reading has found that the most common recommendation is to allocate half a thread to each Nvidia client, however, trying to do this in practice is not possible so I thought that I'd share this, just so that you can see how I've done it..
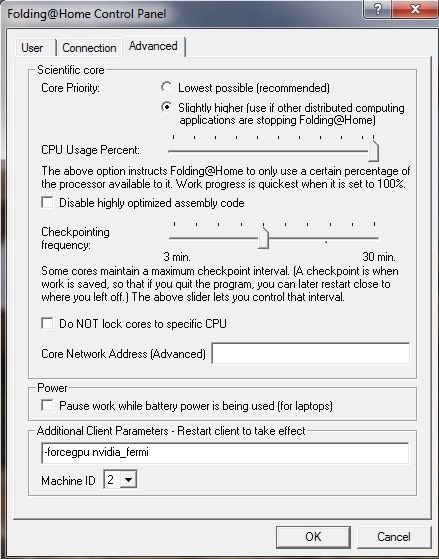
With my Nvivia control panel set up thus:
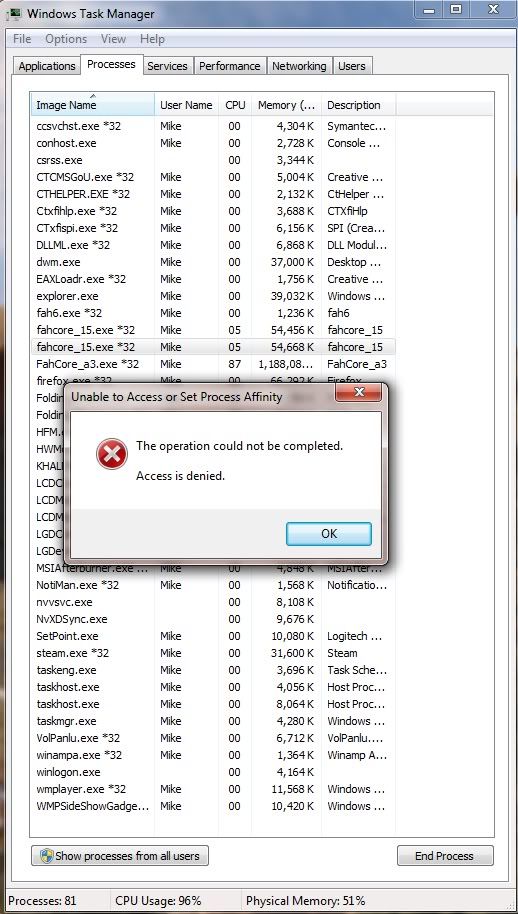
Opening the task manager, then finding the binary being executed by the GPU client is startight forward for me. I have 2 GPU's so I just looked for that which I could see was duplicated, and consuming most resource... FAHCORE_15.exe *32 in my case (I guess that the *32 means it's a 32bit piece of code)
My understanding of this is that the main systray process is called Folding@home.exe and this launches the latest most appropriate CUDA software. I've had NORTON quarantine my FAHCORE_15.exe program when it was first downloaded, so just make sure that your virus checker doesn't intefere by creating an exception by adding it to the trusted list, and restoring it.
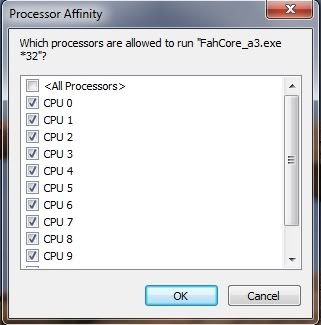
Once FAHCORE_15.exe is running, if you right click on it and try to change the affinity by right clicking on the process and selecting "set affinity" then this will report:
Hmmmm. What do we do?
I noticed that if we try this on the CPU client, that we CAN change the affinity. A little light reading shows that F@H on the GPU uses the core with the most available free cycles - time to test a theory?
Looking at the resource monitor located on the performance tab of the task manager it can be seen that the FAHCORE_15.exe is indeed changig cores. One is executed on Core 3, then the other copy is on core 2, then core 3..... It appeards to be moving dynamically. Good!
On the CPU hosted executable, I right click and set affinity to all but one of my cores...
and then close the task manager.
Now lets check the results:
Before Time per fold with 2 GPU clients and BIGADV on 12 threads: 46mins and upwards (sometimes 1.5hrs)
Time per fold with no GPU client: 23mins or there abouts
Time per fold with 2 GPU clients and BIGADV on 11 threads: 26 mins so far....
That's a considerable improvement if it is sustained....
Will confirm stats and observations over a longer period as they come in...
#UPDATE# Time per fold has now averaged out as 39mins
I'll calculate the relationship to the number of cores next and try to find the optimal setup for the rig.



 Reply With Quote
Reply With Quote






